
Machine translation (MT) is still a huge challenge for both IT developers and users. From the initiation of machine translation, problems at the semantic levels have been faced. Machine translation can be referred to as the process by which computer software is used to translate a text from one natural language (such as English/Afrikaans) to another (such as French/Swahili).
Today despite progress in the development of MT, its systems still fail to recognize which synonym; collocation or word meaning that should be used. Although mobile apps are very popular among users, errors in their translation output create misunderstandings.
The origins of machine translation can be traced back to the work of Al-Kindi, a 9th-century Arabic cryptographer who developed techniques for systematic language translation, including crypt-analysis, frequency analysis, and probability and statistics, which are used in modern machine translation. The idea of machine translation later appeared in the 17th century. The field of machine translation was founded with Warren Weaver’s Memorandum on Translation (1949). The first researcher in the field, Yehosha Bar-Hillel, began his research at MIT (1951). A Georgetown University MT research team followed (1951) with a public demonstration of its Georgetown-IBM experiment system in 1954. MT research programs popped up in Japan and Russia (1955), and the first MT conference was held in London (1956).(wikipedia)
Although computer/technology has stolen the spotlight from humans in many sectors, they aren’t a threat to professional translators. Here are the main reasons why.
Today, we all have access to an automatic translator, and it is also true that we are often tempted to use this tool. But only a couple of uses are enough to realize that these tools are not always effective. This is because they provide literal translations in their raw state, without taking into account cultural and contextual factors, which is essential to any professional translation. This is the main reason why automatic translations often make mistakes.
The type of document

Firstly, translation tools are very general. The reason is simple: they’re supposed to be useful with any type of document. This is where the worst enemy of machine translation tools comes in: ambiguity. You will find below a small example that should make you smile, where the computer obviously unwanted translated “female jacket” in Brazilian PT and into Spanish languages.
Translation model
Another flaw of translation tools lies in the translation model. These tools compare numerous collections of texts and draw translation rules from them. Despite these rules, for each new translation, the professional translator is faced with new issues which only they alone can solve by making choices. These choices cannot be made by the software.

Some examples of machine translation errors:
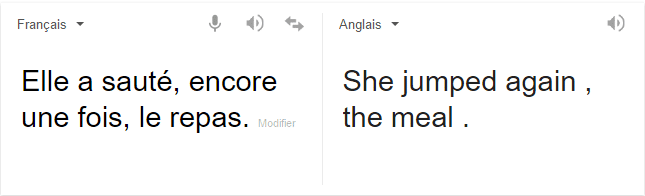
Here’s another example of a machine translation error of a sentence in French that was automatically translated into English
Here, ambiguity has led to a computer error still. The verb “sauter” in French can be translated as to jump, or to skip in English, depending on the context. Unluckily for these far-from-perfect tools, the verb “sauter” was used incorrectly. It should have been used to mean “skip” in order to conserve the original meaning of the sentence.
In addition, in a medical or legal context, a bad translation could have serious consequences.
The results are disappointing, because even after almost 70 years of MT research and improvement, researchers still cannot offer a system that would be able to translate with at least 50% correctness.
Always be cautious of these types of tools. They can be useful in some cases, but their limits must never be overlooked. Our advice to you is to always opt for professional translation services.